ビッグエンディアンモードでのARM NEON命令の使用¶
はじめに¶
ビッグエンディアンARMプロセッサのコード生成は、ほとんどの場合簡単です。しかし、NEONのロードとストアには、ビッグエンディアンモードでのコード生成の決定を分かりにくくするいくつかの興味深い特性があります。
このドキュメントの目的は、NEONのロードとストアの問題とそのLLVMで実装された解決策を説明することです。
このドキュメントでは、「ベクトル」という用語は、ARM ABIが「ショートベクトル」と呼ぶものを指します。これは、NEONレジスタに収まるアイテムのシーケンスです。このシーケンスは、64ビットまたは128ビットの長さで、8、16、32、または64ビットのアイテムで構成されます。このドキュメントではA64命令について説明していますが、A32/ARMv7命令セットにもほぼ適用できます。A32でのベクトルを渡すためのABI形式はA64とは多少異なります。それ以外は、同じ概念が適用されます。
例:Cレベルの組込み関数 -> アセンブリ¶
最初に、CレベルのARM NEON組込み関数が命令にどのようにローワーされるかを示すと役立つ場合があります。
この単純なC関数は、4つのintのベクトルを取り、0番目のレーンを値「42」に設定します。
#include <arm_neon.h>
int32x4_t f(int32x4_t p) {
return vsetq_lane_s32(42, p, 0);
}
arm_neon.hの組込み関数は、可能な限り「汎用」IR(つまり、llvm.arm.neon.*組込み関数呼び出しではない通常のIR命令)を生成します。上記は以下を生成します。
define <4 x i32> @f(<4 x i32> %p) {
%vset_lane = insertelement <4 x i32> %p, i32 42, i32 0
ret <4 x i32> %vset_lane
}
そして、それは次の単純なアセンブリになります。
f: // @f
movz w8, #0x2a
ins v0.s[0], w8
ret
問題¶
主な問題は、ベクトルがメモリとレジスタでどのように表現されるかです。
まず、復習です。「エンディアンネス」は、メモリの表現のみに影響を与えます。レジスタでは、数値は単なるビットのシーケンスです(AArch64の汎用レジスタの場合は64ビット)。しかし、メモリはアドレス可能な8ビット単位のシーケンスです。したがって、8ビットより大きい数値は8ビットのチャンクに分割する必要があり、エンディアンネスはこれらのチャンクがメモリにレイアウトされる順序を表します。
「リトルエンディアン」レイアウトでは、最下位バイトが先頭(メモリアドレスが最も低い)にあります。「ビッグエンディアン」レイアウトでは、最上位バイトが先頭にあります。これは、ビッグエンディアンメモリからアイテムを読み込む場合、メモリ内の最下位8ビットを最上位8ビットに入れる必要があることを意味します。
LDR および LD1¶
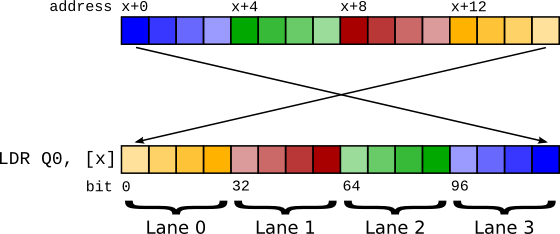
図1 LDRを使用したビッグエンディアンベクトルロード。¶
ベクトルは、同時に操作されるアイテムの連続したシーケンスです。64ビットベクトルを読み込むには、メモリから64ビットを読み取る必要があります。リトルエンディアンモードでは、LDR q0, [foo]という64ビットロードを実行するだけで済みます。しかし、ビッグエンディアンモードでこれを実行しようとすると、バイトスワップのためにレーンインデックスが入れ替わってしまいます!メモリにレイアウトされた0番目のアイテムは、ベクトル内のn番目のレーンになります。
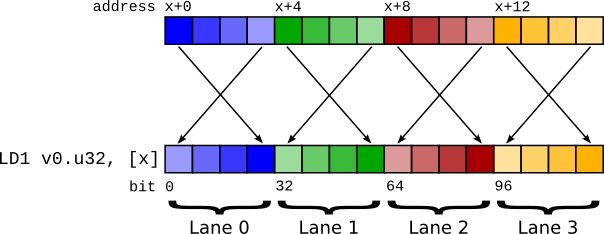
図2 LD1を使用したビッグエンディアンベクトルロード。レーンは正しい順序を維持していることに注意してください。¶
このため、LD1命令はベクトルロードを実行しますが、64ビット全体ではなく、ベクトル内の個々のアイテムでバイトスワップを実行します。これは、レジスタの内容がリトルエンディアンシステムの場合と同じになることを意味します。
LD1でビッグエンディアンマシンでベクトルロードを実行できると思われるかもしれませんが、2つのアプローチには長所と短所があり、どのレジスタ形式を選択するかは単純ではありません。
2つのオプションがあります。
ベクトルレジスタの内容は、
LDR命令でロードした場合と同じです。ベクトルレジスタの内容は、
LD1命令でロードした場合と同じです。
ビッグエンディアンシステムではLD1 == LDR + REVであり、同様にLDR == LD1 + REVであるため、もう一方のロードタイプとREV命令を使用して、いずれかのロードタイプをシミュレートできます。そのため、使用する命令ではなく、使用する形式(そして、それが使用する命令に影響を与える)を決定しています。
このセクション全体を通して、ロードについてのみ説明しています。ストアには、関連付けられたロードと同じ問題があるため、簡潔にするために省略しました。
考慮事項¶
LLVM IR レーンの順序¶
LLVM IRには、ファーストクラスのベクトル型があります。LLVM IRでは、ベクトルの0番目の要素はメモリアドレスが最も低くなります。最適化器は、たとえばベクトルを連結する場合など、特定の領域でこのプロパティに依存します。配列とベクトルは、メモリレイアウトが同一であることが意図されています。- [4 x i8]と<4 x i8>は、メモリで同じように表現される必要があります。このプロパティがないと、最適化器が巧みに処理しなければならない多くの特別なケースが発生します。
LDRの使用はこのレーン順序プロパティを壊します。LDRの使用を妨げるものではありませんが、次の2つのいずれかを行う必要があります。
すべての
LDRの後でレーン順序を反転するREV命令を挿入します。レーンレイアウトに依存するすべての最適化を無効にし、個々のレーンへのアクセスごとに(
insertelement/extractelement/shufflevector)レーンインデックスを反転します。
AAPCS¶
ARMプロシージャコール標準(AAPCS)は、レジスタ間でベクトルを渡すためのABIを定義しています。それは次のように述べています。
ショートベクトルがレジスタとメモリ間で転送されるとき、それは不透明なオブジェクトとして扱われます。つまり、ショートベクトルは、レジスタ全体を単一の
STRで格納した場合のようにメモリに格納されます。ショートベクトルは、対応するLDR命令を使用してメモリからロードされます。リトルエンディアンシステムでは、要素0は常にショートベクトルのアドレスが最も低い要素を含みます。ビッグエンディアンシステムでは、要素0はショートベクトルのアドレスが最も高い要素を含みます。—ARM 64ビットアーキテクチャ(AArch64)のプロシージャコール標準、4.1.2 ショートベクトル
LDRとSTRをABIとして使用することには、LD1とST1よりも少なくとも1つの利点があります。LDRとSTRは、ベクトルの個々のレーンのサイズを意識しません。LD1とST1はそうではありません。レーンサイズはそれらの中にエンコードされています。これはABI境界を越えて重要です。なぜなら、呼び出し元が期待するレーン幅を知る必要があるからです。次のコードを考えてみてください。
<callee.c>
void callee(uint32x2_t v) {
...
}
<caller.c>
extern void callee(uint32x2_t);
void caller() {
callee(...);
}
もしcalleeがシグネチャをuint16x4_tに変更した場合、これはレジスタの内容では等価ですが、LD1として渡すと、callerが更新および再コンパイルされるまでこのコードが壊れます。
2つの関数のシグネチャが異なれば、動作は未定義であるという議論があります。しかし、ベクトルのレーンレイアウトに無関係な関数があり、ベクトルを不透明な値として扱う(単にロードしてストアする)には、ABI境界を跨いで共通のフォーマットがないと不可能です。
そのため、ABI互換性を維持するために、関数呼び出し全体でLDRレーンレイアウトを使用する必要があります。
アラインメント¶
厳密なアラインメントモードでは、LDR qXはアドレスが128ビットアラインメントされている必要がありますが、LD1はレーンサイズと同じアラインメントで十分です。LDRの使用を標準化する場合でも、アラインメント違反(LD1の結果はREVで反転する必要があります)を回避するために、いくつかの場所でLD1を使用する必要があります。
ただし、ほとんどのオペレーティングシステムはアラインメント違反を有効にして実行されていないため、これは多くの場合問題になりません。
概要¶
次の表は、上記の各プロパティについて、2つのソリューションそれぞれに必要な命令をまとめたものです。
|
|
|
|---|---|---|
レーン順序 |
|
|
AAPCS |
|
|
厳密モードのアラインメント |
|
|
どちらのアプローチも完璧ではなく、どちらかを選択することは、より小さな悪を選ぶことに帰着します。レーン順序の問題については、ターゲットに依存しないコンパイラのパスを変更する必要があり、レーンインデックスが反転した奇妙なIR(中間表現)になるため、変更が必要であると判断されました。これは、LD1をサポートするために必要な変更よりも悪いと判断されたため、LD1が標準のベクトルロード命令(そして、推論によって、ベクトルストアにはST1)として選択されました。
実装¶
実装には3つの部分があります。
ベクトルロードとストアの生成に選択されないように、述語
LDRとSTR命令を指定します。例外は1レーンベクトル[1]です。これらは定義上、レーン順序の問題がないため、LDR/STRを使用しても問題ありません。
REV命令を作成するビットコンバート用のコード生成パターンを作成します。ベクトル値が関数呼び出しの境界を越えて1要素ベクトルとして渡されるように、適切なビットコンバートが作成されていることを確認します(これは
LDRでロードした場合と同じです)。
ビットコンバート¶
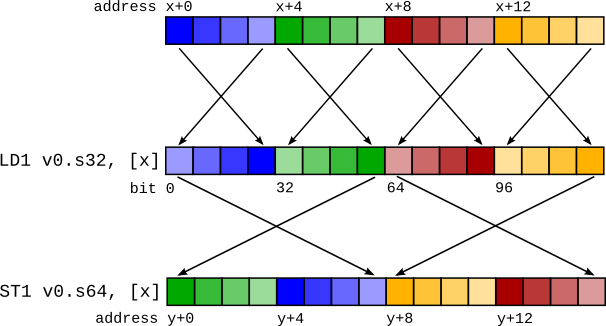
LD1ソリューションの主な問題は、ビットコンバート(またはビットキャスト、またはreinterpretキャスト)の処理です。これらは、基になるデータではなく、コンパイラのデータの解釈のみを変更する擬似命令です。要件は、データがロードされてから再び保存される場合(「ラウンドトリップ」と呼ばれる)、ストア後のメモリの内容はロード前と同じである必要があります。ベクトルがロードされてから、ストアする前に異なるベクトル型にビットコンバートされると、ラウンドトリップは現在破損します。
たとえば、次のコードシーケンスを考えてみましょう。
%0 = load <4 x i32> %x
%1 = bitcast <4 x i32> %0 to <2 x i64>
store <2 x i64> %1, <2 x i64>* %y
これにより、右側の図のようなコードシーケンスが生成されます。LD1とST1の不一致により、保存されたデータがロードされたデータと異なります。
型Xから型Yへのビットキャストが見つかった場合、行う必要があるのは、データのレジスタ内表現を、型YのLD1でロードされたかのように変更することです。
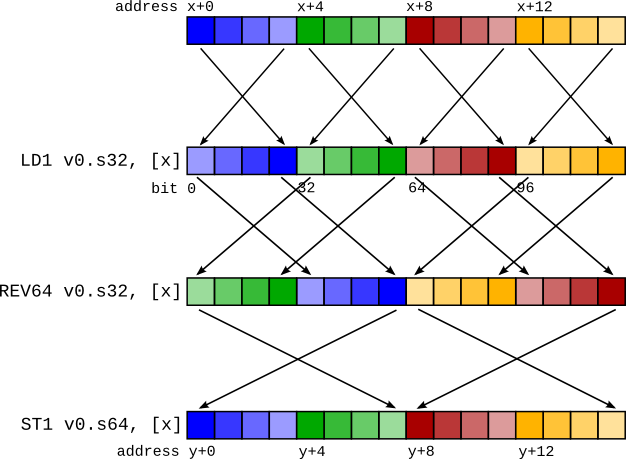
概念的にはこれは簡単です。型XのLD1を元に戻すREV(レジスタ内表現をLDRでロードされたものと同じに変換する)を挿入し、次に別のREVを挿入して、型YのLD1でロードされたもののように表現を変更します。
前の例では、これは次のようになります。
LD1 v0.4s, [x]
REV64 v0.4s, v0.4s // There is no REV128 instruction, so it must be synthesizedcd
EXT v0.16b, v0.16b, v0.16b, #8 // with a REV64 then an EXT to swap the two 64-bit elements.
REV64 v0.2d, v0.2d
EXT v0.16b, v0.16b, v0.16b, #8
ST1 v0.2d, [y]
これらのREVのペアは、ほとんどの場合、単一のREVに圧縮できます。上記の例では、REV128 4s + REV128 2dは実際にはREV64 4sです(右側の図を参照)。