投機的ロードの強化¶
Spectre Variant #1 緩和手法¶
著者: Chandler Carruth - chandlerc@google.com
問題の記述¶
最近、Google Project Zeroと他の研究者は、最新のCPUの投機的実行を利用した情報漏洩の脆弱性を発見しました。これらのエクスプロイトは現在、3つのバリアントに分類されています。
GPZ バリアント #1 (別名 Spectre バリアント #1): 境界チェック (または述語) バイパス
GPZ バリアント #2 (別名 Spectre バリアント #2): 分岐ターゲットインジェクション
GPZ バリアント #3 (別名 Meltdown): 不正規データキャッシュロード
詳細については、Google Project Zeroのブログ投稿とSpectreの研究論文を参照してください。
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
https://spectreattack.com/spectre.pdf
GPZ バリアント #1 の中心的な問題は、投機的実行が分岐予測を使用して、投機的に実行される命令のパスを選択することです。このパスは利用可能なデータで投機的に実行され、メモリからロードし、間違っているために投機的実行が巻き戻された場合でも存続するさまざまなサイドチャネルを介してロードされた値をリークする可能性があります。誤って予測されたパスは、正しい実行では発生しないデータ入力でコードが実行される原因となり、悪意のある入力に対するチェックを無効にし、攻撃者が悪意のあるデータ入力を使用して秘密データをリークできるようにします。Project Zeroの論文から抜粋して簡略化した例を次に示します。
struct array {
unsigned long length;
unsigned char data[];
};
struct array *arr1 = ...; // small array
struct array *arr2 = ...; // array of size 0x400
unsigned long untrusted_offset_from_caller = ...;
if (untrusted_offset_from_caller < arr1->length) {
unsigned char value = arr1->data[untrusted_offset_from_caller];
unsigned long index2 = ((value&1)*0x100)+0x200;
unsigned char value2 = arr2->data[index2];
}
攻撃の鍵は、分岐予測器がインバウンドになると予測する場合、境界をはるかに超えている untrusted_offset_from_caller を使用してこれを呼び出すことです。その場合、if の本体は投機的に実行され、秘密データを value に読み込み、依存アクセスが value2 を設定するために行われたときにキャッシュタイミングサイドチャネルを介してリークする可能性があります。
高レベルの緩和アプローチ¶
特に危険なソフトウェア (特にさまざまなOSカーネル) 内の特定の分岐やロードを軽減するために、いくつかのアプローチが積極的に追求されていますが、これらのアプローチでは、コードの手動および/または静的分析による監査と、緩和策を適用するため明示的なソースの変更が必要です。これらは、大規模なアプリケーションにうまくスケールする可能性は低いでしょう。コードを手動で変更するのではなく、プログラム全体に自動的に適用される包括的な緩和アプローチを提案しています。これは高いパフォーマンスコストがかかる可能性がありますが、一部のアプリケーションはこのパフォーマンス/セキュリティのトレードオフを行うのに適している場合があります。
私たちが提案する具体的な手法は、分岐のないコードを使用してロードをチェックし、有効な制御フローパスに沿って実行されていることを確認することです。潜在的に無効なロードを保護する述語の中心的なアイデアを表す次のC疑似コードを考えてみましょう。
void leak(int data);
void example(int* pointer1, int* pointer2) {
if (condition) {
// ... lots of code ...
leak(*pointer1);
} else {
// ... more code ...
leak(*pointer2);
}
}
これは、次のようなものに変換されます。
uintptr_t all_ones_mask = std::numerical_limits<uintptr_t>::max();
uintptr_t all_zeros_mask = 0;
void leak(int data);
void example(int* pointer1, int* pointer2) {
uintptr_t predicate_state = all_ones_mask;
if (condition) {
// Assuming ?: is implemented using branchless logic...
predicate_state = !condition ? all_zeros_mask : predicate_state;
// ... lots of code ...
//
// Harden the pointer so it can't be loaded
pointer1 &= predicate_state;
leak(*pointer1);
} else {
predicate_state = condition ? all_zeros_mask : predicate_state;
// ... more code ...
//
// Alternative: Harden the loaded value
int value2 = *pointer2 & predicate_state;
leak(value2);
}
}
結果は、if (condition) { 分岐が誤って予測された場合、それらを介してロードする前にポインタをゼロにするために使用される条件、またはロードされたすべてのビットをゼロにするために使用される条件に*データ*依存関係があるはずです。このコードパターンは依然として投機的に実行される可能性がありますが、 *無効な*投機的実行は、メモリからの機密データのリークを防ぎます(ただし、このデータは安全な方法でロードされる可能性があり、メモリの一部の領域は機密情報を保持しないようにする必要があります。詳細な制限については以下を参照してください)。このアプローチでは、基盤となるハードウェアが、レジスタの値を分岐なしで予測不可能な条件付き更新を実装する方法を持っていることだけが必要です。すべての最新のアーキテクチャはこれをサポートしており、実際、このようなサポートは一定時間の暗号プリミティブを正しく実装するために必要です。
このアプローチの重要な特性
特定のサイドチャネルが機能するのを防ぐものではありません。これは、潜在的なサイドチャネルの数が不明であり、今後もさらに発見されると予想されるため、重要です。代わりに、そもそも機密データの観察を防ぎます。
述語状態を累積し、ネストされた*正しく*予測された制御フローに直面しても保護します。
この述語状態を関数境界を越えて渡し、手続き間保護を提供します。
ロードのアドレスを強化する場合、*破壊的*または*不可逆的*なアドレスの変更を使用して、攻撃者が攻撃者制御の入力を使用してチェックを元に戻すのを防ぎます。
投機的実行を完全にブロックするのではなく、*誤って*推測されたパスがメモリから機密情報をリークするのを防ぐだけです(そして、これが決定されるまで推測を停止します)。
完全に一般的であり、分岐のない条件付きデータ更新と値予測の欠如を行うことができることを除いて、基礎となるアーキテクチャについて基本的な仮定を行いません。
プログラマーは、静的ソースコード注釈またはバリアント#1スタイルの攻撃に対して脆弱なコードを使用して、すべての可能な機密データを識別する必要はありません。
このアプローチの制限
強化命令シーケンスを挿入するには、ソースコードを再コンパイルする必要があります。このモードでコンパイルされたソフトウェアのみが保護されます。
パフォーマンスは、特定のアーキテクチャの実装戦略に大きく依存します。以下に、潜在的なx86実装の概要とパフォーマンス特性を示します。
メモリからすでにロードされ、レジスタに存在する、または非投機的実行における他のサイドチャネルを介してリークされた機密データは保護されません。これを処理するコード、例えば暗号化ルーチンは、すでに一定時間アルゴリズムとコードを使用してサイドチャネルを防いでいます。このようなコードは、これらのガイドラインに従って、機密データのレジスタをスクラブする必要があります。
妥当なパフォーマンスを実現するために、コンパイル時固定アドレスを持つロードなど、多くのロードがチェックされない場合があります。これは主に、グローバル変数とローカル変数のコンパイル時定数オフセットでのアクセスで構成されます。この保護を必要とし、意図的に機密データを保存するコードは、機密データに使用されるメモリ領域が必然的に動的マッピングまたはヒープ割り当てであることを確認する必要があります。これは、パフォーマンスを犠牲にしてより包括的な保護を提供するために調整できる領域です.
強化されたロードは、*攻撃者制御の*アドレスでなくても、*有効な*アドレスからデータをロードする可能性があります。これらが機密データを読み取るのを防ぐために、アドレス空間の下位2GBと、実行可能ページの2GB上下を保護する必要があります。
クレジット
データによる誤った推測を追跡し、誤って推測されたロードをブロックするためにポインタをマーキングするという中心的なアイデアは、Chandler Carruth、Paul Kocher、Thomas Pornin、および他の数人の個人とのHACS 2018ディスカッションの一環として開発されました。
ロードされたビットをマスキングするという中心的なアイデアは、これらの攻撃が報告されたときにJann Hornによって提案された元の緩和策の一部でした。
間接分岐、呼び出し、および戻り¶
バリアント#1スタイルの誤予測で条件分岐以外の制御フローを攻撃することが可能です。
仮想メソッドのホットコールターゲットに対する予測は、予期される型が使用されたときに投機的に実行される可能性があります(多くの場合、「型の混乱」と呼ばれます)。
ジャンプテーブルとして実装されたswitch文の正しいケースの代わりに、ホットケースが予測のために投機的に実行される場合があります。
関数から戻る際に、ホットコモンリターンアドレスが誤って予測される場合があります.
これらのコードパターンはSpectreバリアント#2にも脆弱であるため、x86プラットフォームではretpolineで軽減するのが最適です。retpolineのような緩和手法が使用されると、推測は単に間接制御フローエッジを通過できません(または、満たされたRSBの場合、誤って予測されることはできません)。そのため、バリアント#1スタイルの攻撃からも保護されます。ただし、一部のアーキテクチャ、マイクロアーキテクチャ、またはベンダーはretpolineの緩和策を採用しておらず、将来のx86ハードウェア(IntelとAMDの両方)では、ハードウェアベースの緩和策により不要になると予想されています。
retpolineを使用しない場合、これらのエッジはバリアント#1スタイルの攻撃から独立した保護を必要とします。条件付き制御フローに使用されるのと同様のアプローチが機能するはずです。
uintptr_t all_ones_mask = std::numerical_limits<uintptr_t>::max();
uintptr_t all_zeros_mask = 0;
void leak(int data);
void example(int* pointer1, int* pointer2) {
uintptr_t predicate_state = all_ones_mask;
switch (condition) {
case 0:
// Assuming ?: is implemented using branchless logic...
predicate_state = (condition != 0) ? all_zeros_mask : predicate_state;
// ... lots of code ...
//
// Harden the pointer so it can't be loaded
pointer1 &= predicate_state;
leak(*pointer1);
break;
case 1:
predicate_state = (condition != 1) ? all_zeros_mask : predicate_state;
// ... more code ...
//
// Alternative: Harden the loaded value
int value2 = *pointer2 & predicate_state;
leak(value2);
break;
// ...
}
}
中心的なアイデアは同じままです。データフローを使用して制御フローを検証し、その検証を使用して、ロードが誤って推測されたパスに沿って情報をリークできないことを確認します。通常、これは、このような制御フローの目的のターゲットをエッジを越えて渡し、その後でそれが正しいことを確認することを含みます。これはバリアント#2の攻撃を軽減すると考えるのは魅力的ですが、そうではありません。これらの攻撃は、チェックを含まない任意のガジェットにアクセスします。
バリアント#1.1および#1.2攻撃:「境界チェックバイパスストア」¶
コアバリアント#1攻撃以外にも、この攻撃を拡張する手法があります。主な手法は「境界チェックバイパスストア」として知られており、この研究論文で説明されています。https://people.csail.mit.edu/vlk/spectre11.pdf
これらの2つのバリアントを個別に分析します。まず、バリアント#1.1は、境界チェックバイパスの後にリターンアドレスに投機的に格納することによって機能します。この投機的ストアは、戻りの投機的実行中にCPUによって使用され、投機的実行をバイナリ内の任意のガジェットに指示する可能性があります。例を見てみましょう。
unsigned char local_buffer[4];
unsigned char *untrusted_data_from_caller = ...;
unsigned long untrusted_size_from_caller = ...;
if (untrusted_size_from_caller < sizeof(local_buffer)) {
// Speculative execution enters here with a too-large size.
memcpy(local_buffer, untrusted_data_from_caller,
untrusted_size_from_caller);
// The stack has now been smashed, writing an attacker-controlled
// address over the return address.
minor_processing(local_buffer);
return;
// Control will speculate to the attacker-written address.
}
ただし、これは他のロードと同様にリターンアドレスのロードを強化することで軽減できます。これは、たとえばx86がスタックからリターンアドレスを*暗黙的に*ロードするため、複雑になる場合があります。ただし、以下の実装手法は、スタックポインタを使用して関数間で誤った推測を伝達することにより、この暗黙のロードを軽減するように特別に設計されています。これにより、さらに、誤った推測によって無効なスタックポインタが発生し、投機的に格納されたリターンアドレスを読み取ることができなくなります。以下の詳細な説明を参照してください。
バリアント#1.2の場合、攻撃者は間接呼び出しまたは間接ジャンプを実装するために使用されるvtableまたはジャンプテーブルに投機的に格納します。これは投機的であるため、これらが読み取り専用ページに格納されている場合でも、これは多くの場合可能です。例えば
class FancyObject : public BaseObject {
public:
void DoSomething() override;
};
void f(unsigned long attacker_offset, unsigned long attacker_data) {
FancyObject object = getMyObject();
unsigned long *arr[4] = getFourDataPointers();
if (attacker_offset < 4) {
// We have bypassed the bounds check speculatively.
unsigned long *data = arr[attacker_offset];
// Now we have computed a pointer inside of `object`, the vptr.
*data = attacker_data;
// The vptr points to the virtual table and we speculatively clobber that.
g(object); // Hand the object to some other routine.
}
}
// In another file, we call a method on the object.
void g(BaseObject &object) {
object.DoSomething();
// This speculatively calls the address stored over the vtable.
}
これを軽減するには、これらの場所からのロードを強化するか、間接呼び出しまたは間接ジャンプを軽減する必要があります。これらのいずれかで、呼び出しまたはジャンプが読み取られた投機的に格納された値を使用するのをブロックするのに十分です。
これらのどちらの場合でも、retpolineを使用すれば同等に十分です。考えられるハイブリッドアプローチの1つは、間接呼び出しとジャンプにretpolineを使用し、リターンを軽減するためにSLHに依存することです。
これらのどちらにも有効なもう1つのアプローチは、すべての投機的ストアを強化することです。しかし、ほとんどのストアは重要ではなく、本質的にデータをリークしないため、防御対象の攻撃を考えると、これは非常にコストがかかると予想されます。
実装の詳細¶
この手法の実装には、特定のアーキテクチャと特定のコンパイラの両方において、影響を与える複雑な詳細が多数あります。ここでは、x86アーキテクチャとLLVMコンパイラのための提案されている実装手法について説明します。これらは主に例として示すものであり、他の実装手法も非常に可能です。
x86実装の詳細¶
x86プラットフォームでは、実装を3つの主要コンポーネントに分割します。制御フローグラフを介した述語状態の累積、ロードのチェック、およびプロシージャ間の制御転送のチェックです。
述語状態の累積¶
以下のような基本的なx86命令を考えてみましょう。これは3つの条件をテストし、すべてが合格した場合、メモリからデータをロードし、何らかのサイドチャネルを介してリークする可能性があります。
# %bb.0: # %entry
pushq %rax
testl %edi, %edi
jne .LBB0_4
# %bb.1: # %then1
testl %esi, %esi
jne .LBB0_4
# %bb.2: # %then2
testl %edx, %edx
je .LBB0_3
.LBB0_4: # %exit
popq %rax
retq
.LBB0_3: # %danger
movl (%rcx), %edi
callq leak
popq %rax
retq
ロードを投機的に実行する場合、動的に実行された述語のいずれかが誤って推測されたかどうかを知りたいと考えています。それを追跡するために、各条件分岐に沿って、その分岐を取ることができるデータを追跡する必要があります。 x86では、このデータは条件付きジャンプ命令で使用されるフラグレジスタに格納されます。制御フローのこの分岐後の両方のエッジに沿って、フラグレジスタは有効なままであり、累積された述語状態を構築するために使用できるデータが含まれています。状態が存在するフラグレジスタも読み取るx86条件付き移動命令を使用して、それを累積します。これらの条件付き移動命令は、どのx86プロセッサでも予測されないことが知られており、脆弱性を再導入する可能性のある誤予測の影響を受けません。条件付き移動を挿入すると、コードは次のようになります。
# %bb.0: # %entry
pushq %rax
xorl %eax, %eax # Zero out initial predicate state.
movq $-1, %r8 # Put all-ones mask into a register.
testl %edi, %edi
jne .LBB0_1
# %bb.2: # %then1
cmovneq %r8, %rax # Conditionally update predicate state.
testl %esi, %esi
jne .LBB0_1
# %bb.3: # %then2
cmovneq %r8, %rax # Conditionally update predicate state.
testl %edx, %edx
je .LBB0_4
.LBB0_1:
cmoveq %r8, %rax # Conditionally update predicate state.
popq %rax
retq
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
...
ここでは、%raxをゼロにすることで「空の」または「正しい実行」述語状態を作成し、%r8に-1を入れて定数「不正な実行」述語値を作成します。次に、条件分岐から出てくる各エッジに沿って、正しい実行ではノーオペレーションになる条件付き移動を実行しますが、誤って推測された場合は、%raxを%r8の値で置き換えます。 3つの述語のいずれかを誤って推測すると、実行が正しい場合は上書きするのではなく着信値を保持するため、%raxは%r8からの「不正な実行」値を保持します。
これで、各基本ブロックの%raxに、以前に述語が誤って予測されたかどうかを示す値ができました。そして、その値が以下で使用されてロードを強化するときに特に効果的になるように配置しました。
間接呼び出し、分岐、およびリターンの述語¶
間接呼び出し、分岐、およびリターンを追跡する場合に使用する類似のフラグはありません。述語状態は、他の手段によって累積する必要があります。基本的に、これはCFIで提起された問題の逆です。どこに行くのではなく、どこから来たのかを確認する必要があります。関数ローカルジャンプテーブルの場合、これは各宛先内でジャンプテーブルの入力をテストすることで簡単に配置できます(まだ実装されていません。retpolineを使用してください)。
pushq %rax
xorl %eax, %eax # Zero out initial predicate state.
movq $-1, %r8 # Put all-ones mask into a register.
jmpq *.LJTI0_0(,%rdi,8) # Indirect jump through table.
.LBB0_2: # %sw.bb
testq $0, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
.LBB0_3: # %sw.bb1
testq $1, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
.LBB0_5: # %sw.bb10
testq $2, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
...
.section .rodata,"a",@progbits
.p2align 3
.LJTI0_0:
.quad .LBB0_2
.quad .LBB0_3
.quad .LBB0_5
...
リターンには、x86-64(またはスタックの 끝 を超えた「レッドゾーン」領域と呼ばれるものを持つ他のABI)に簡単な軽減策があります。この領域は、割り込みとコンテキストスイッチ全体で保持されることが保証されているため、現在のコードへの復帰に使用されるリターンアドレスはスタック上に残り、読み取りに有効です。呼び出し側でコードを発行して、リターンエッジが誤って予測されていないことを確認できます。
callq other_function
return_addr:
testq -8(%rsp), return_addr # Validate return address.
cmovneq %r8, %rax # Update predicate state.
「レッドゾーン」のないABI(したがってスタックからリターンアドレスを読み取ることができない)の場合、呼び出しの前に予期されるリターンアドレスを呼び出し全体で保持されるレジスタに計算し、上記と同様に使用できます。
間接呼び出し(およびレッドゾーンABIがない場合のリターン)は、伝播する上で最も重要な課題をもたらします。最も簡単な手法は、意図した呼び出しターゲットが呼び出された関数に渡され、エントリでチェックされるように新しいABIを定義することです。残念ながら、新しいABIはCおよびC ++にデプロイするには非常にコストがかかります。ターゲット関数をTLSで渡すことはできますが、この追加ロジックの有無にかかわらずコンパイルされた関数の混合を処理するための複雑なロジックが依然として必要になります(基本的に、ABIを下位互換にします)。現在、ここではretpolineを使用することをお勧めし、これを軽減する方法を引き続き調査します。
最適化、代替案、およびトレードオフ¶
述語状態を累積するだけでは、かなりのコストがかかります。これを最小限に抑えるために採用しているいくつかの重要な最適化と、生成されたコードに異なるトレードオフをもたらすさまざまな代替手段があります。
まず、状態を追跡するために使用される命令の数を減らすように努めます。
元のプログラムのすべての条件分岐に沿って
cmovCC命令を挿入するのではなく、各基本ブロックに入る前にキャプチャする必要がある条件フラグの各セットを追跡し、それらに共通のcmovCCシーケンスを再利用します。フラグのセットをキャプチャするために複数の
cmovCC命令が必要な場合、サフィックスをさらに再利用できます。現在、これは、ペアになったフラグが比較的まれであり、それらのサフィックスが非常にまれであるため、コストに見合わないと考えられています。
x86の一般的なパターンは、同じフラグを使用するが異なる条件を処理する複数の条件付きジャンプ命令を持つことです。単純に、それらの間の各フォールスルーを「エッジ」と見なすことができますが、これははるかに複雑な制御フローグラフを引き起こします。代わりに、フォールスルーに必要な条件のセットを累積し、単一のフォールスルーエッジで
cmovCC命令のシーケンスを使用して追跡します。
次に、「不正な」状態にレジスタを割り当てることで、レジスタのプレッシャーとより単純なcmovCC命令を交換します。条件付き移動命令の一部としてメモリからその値を読み取ることができますが、これによりマイクロオペレーションが増え、ロードストアユニットが関与する必要があります。現在、値を仮想レジスタに配置し、レジスタアロケータがレジスタのプレッシャーがメモリにスピルしてリロードするのに十分かどうかを判断できるようにします。
ロードの強化¶
述語が正しいか誤って推測されたかを示す特別な値に累積されると、秘密データがリークしないようにロードに適用する必要があります。これには、主に2つの手法があります。ロードされた値を強化して観測を防ぐか、アドレス自体を強化してロードが発生しないようにすることができます。これらには、パフォーマンスのトレードオフが大きく異なります。
ロードされた値の強化¶
ロードを強化する最も魅力的な方法は、ロードされたすべてのビットをマスクすることです。重要な要件は、ロードされた各ビットについて、誤って推測されたパスに沿って、そのビットがロードされたビットの値に関係なく常に0または1に固定されることです。最も明白な実装では、誤って推測されたパスに沿ってすべてゼロのマスクと正しいパスに沿ってすべて1のマスクを持つand命令、または誤って推測されたパスに沿ってすべて1のマスクと正しいパスに沿ってすべてゼロのマスクを持つor命令を使用します。ゼロで乗算したり、複数のシフト命令を使用したりするなど、他のオプションはそれほど魅力的ではなくなります。以下で詳しく説明する理由により、すべて1のマスクでorを使用することをお勧めします。これにより、x86命令シーケンスは次のようになります。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
movl (%rsi), %edi # Load potentially secret data from %rsi.
orl %eax, %edi
他の有用なパターンは、レジスタからレジスタへのコピーのコストで、ロードをor命令自体に折りたたむことです。
このアプローチの展開には、いくつかの課題があります。
x86の多くのロードは、他の命令に折りたたまれています。それらを分離すると、非常に大きくコストのかかるレジスタプレッシャーが発生し、パフォーマンスコストが法外なものになります。
ロードは、状態値を正しいレジスタクラスにマッピングするための追加の命令、および場合によっては値を何らかの方法でマスクするためのより高価な命令を必要とする汎用レジスタをターゲットにしない場合があります。
x86のフラグレジスタは有効である可能性が高く、安価に保存するのは困難です。
ロードに使用されるポインタとインデックスよりも、ロードされる値の方がはるかに多くなります。その結果、ロードの結果を強化するには、ロードのアドレスを強化するよりもはるかに多くの命令が必要です(以下を参照)。
これらの課題にもかかわらず、ロードの結果を強化することで、ロードを続行できるため、実行の投機的/アウトオブオーダーの可能性全体への影響が劇的に少なくなります。これらの課題を軽減し、少なくとも場合によってはロードの結果の強化を実行可能にするための興味深い手法もいくつかあります。ただし、一般的には、ロードされた値の強化から、アドレス自体の強化という次のアプローチに、利益が得られない場合はフォールバックすることが予想されます。
データ不変操作に折りたたまれたロードは、操作後に強化できます¶
この手法を実現するための最初の鍵は、x86における多くの演算が「データ不変」であることを認識することです。つまり、特定の入力データによって観測可能な動作の違いがない(既知のものが存在しない)ということです。これらの命令は、サイドチャネルを提供しないと信じられているため、秘密鍵データを扱う暗号プリミティブを実装する際にしばしば使用されます。同様に、これらの命令はそれ自体では投機的実行サイドチャネルを導入しないため、対策は後回しにすることができます。これにより、以下のようなコードシーケンスが得られます。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate without leaking.
orl %eax, %edi
ロードされた(潜在的に秘密の)値に加算が行われますが、これはデータをリークせず、直後に対策を適用します。
データ不変式グラフにおけるロード値の対策の遅延¶
前のアイデアを一般化し、データ不変演算をできるだけ多く横断して、式グラフの下流にハードニングを沈めることができます。これは、何かがデータ不変であるかどうかに関して、非常に保守的なルールを使用できます。主な目標は、単一の対策命令で複数のロードを処理することです。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate without leaking.
addl 4(%rsi), %edi # Continue without leaking.
addl 8(%rsi), %edi
orl %eax, %edi # Mask out bits from all three loads.
Haswell、Zen、およびそれ以降のプロセッサでロードされた値を対策する際にフラグを保持する¶
残念ながら、x86には、フラグレジスタに触れずに64ビットすべてにマスクを適用する有用な命令はありません。ただし、ワードよりも狭い(32ビットシステムでは32ビット未満、64ビットシステムでは64ビット未満)ロード値は、値をフルワードサイズにゼロ拡張してから、BMI2のshrx命令を使用して元のビット数以上右シフトすることで対策できます。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate 32 bits of data.
shrxq %rax, %rdi, %rdi # Shift out all 32 bits loaded.
x86ではゼロ拡張は無料であるため、これはロードされた値を効率的に対策できます。
ロードのアドレスの対策¶
ロードされた値の対策が適用できない場合、ほとんどの場合、命令が直接情報をリークするため(cmpやjmpqなど)、ロードされた値の代わりにロードの*アドレス*を対策します。これにより、ロードを展開したり、他の高コストを支払ったりすることによってレジスタプレッシャーが増加することを回避できます。
これが実際にどのように機能するかを理解するには、x86のアドレッシングモードの正確なセマンティクスを調べる必要があります。その一般的な形式は、(%base,%index,scale)offsetです。ここで、%baseと%indexは、潜在的に任意の値になり得る64ビットレジスタであり、攻撃者によって制御される可能性があり、scaleとoffsetは固定の即値です。scaleは1、2、4、または8でなければならず、offsetは任意の32ビット符号拡張値です。アドレスを見つけるために実行される正確な計算は、64ビットの2の補数モジュラー演算の下で、%base + (scale * %index) + offsetです。
このアプローチの問題点の1つは、対策後、`%base + (scale *
大きな正のoffsetは、アドレス空間の最初の2ギガバイト内のメモリをインデックス化します。これらのオフセットは攻撃者によって制御されませんが、攻撃者は、目的のオフセットを持つロードを攻撃することを選択し、その領域のメモリを正常に読み取ることができます。これは攻撃者への負担を大幅に増加させ、攻撃の範囲を制限しますが、攻撃を排除するわけではありません。攻撃を完全に阻止するには、オペレーティングシステムと連携して、アドレス空間の下位2ギガバイトにメモリをマッピングすることを禁止する必要があります。
64ビットロードチェック命令¶
ロードをチェックするために、次の命令シーケンスを使用できます。これらの例では、%r8を-1の特殊値を保持するように設定します。これは、誤って推測されたパスで%raxにcmovされます。
単一レジスタアドレッシングモード
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rsi # Mask the pointer if misspeculating.
movl (%rsi), %edi
2レジスタアドレッシングモード
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rsi # Mask the pointer if misspeculating.
orq %rax, %rcx # Mask the index if misspeculating.
movl (%rsi,%rcx), %edi
これにより、ゼロ付近の負のアドレス、またはoffsetがアドレス空間を小さな正のアドレスにラップアラウンドする結果になります。小さな負のアドレスは、ほとんどのオペレーティングシステムのユーザーモードでフォールトしますが、上位アドレス空間をユーザーがアクセスできるようにする必要があるターゲットは、上記で使用されている正確なシーケンスを調整する必要がある場合があります。さらに、ロードを完全に保護するには、OSによって低アドレスを読み取り不可としてマークする必要があります。
RIP相対アドレッシングはさらに簡単に破られる¶
チェックするのがかなり難しい一般的なアドレッシングモードのイディオムがあります。命令ポインタに対する相対アドレッシングです。命令ポインタレジスタの値を変更することはできないため、%indexのみを変更することで、%base + scale * %index + offsetを無効なアドレスに強制するという、より難しい問題があります。私たちが持っている唯一の利点は、攻撃者も%baseを変更できないことです。上記の高速命令シーケンスを使用するが、インデックスにのみ適用する場合、常に%rip + (scale * -1) + offsetにアクセスします。攻撃者がこのアドレスで秘密データを指すロードを見つけることができれば、攻撃者はそれに到達できます。ただし、ローダーとベースライブラリは、下位2GBのアドレス空間を予約できるのと同様に、プログラム内のテキストの2GB以内にヒープ、データセグメント、またはスタックをマッピングすることを拒否することもできます。
フラグレジスタは再びすべてを難しくする¶
orq命令を使用する手法には、x86に重大な欠陥があります。状態を簡単に蓄積できるというまさにそのことが、述語を含むフラグレジスタがここで深刻な問題を引き起こします。ロード命令または後続の命令によって有効で、使用されている可能性があるためです。x86では、orq命令はフラグを**設定**し、既に存在するものを上書きします。これにより、命令ストリームに挿入することが非常に危険になります。残念ながら、ロードされた値を対策する場合とは異なり、ここではフォールバックがないため、完全に一般的なアプローチが必要です。
これらのシーケンスを生成するときに最初にやらなければならないことは、周囲のコードを分析して、フラグが実際には有効ではなく、使用されていないことを証明することです。通常、フラグレジスタを(私たちのものと同様に!)設定するだけで、実際の依存関係なしに設定する他の命令によって設定されています。このような場合、これらの命令を直接挿入しても安全です。あるいは、使用されている値を上書きしないように、それらを earlier に移動できる場合があります。
ただし、これは最終的に不可能な場合があります。その場合、これらの命令の周囲のフラグを保持する必要があります。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
pushfq
orq %rax, %rcx # Mask the pointer if misspeculating.
orq %rax, %rdx # Mask the index if misspeculating.
popfq
movl (%rcx,%rdx), %edi
pushfおよびpopf命令を使用すると、挿入されたコードの周囲のフラグレジスタが保存されますが、高コストです。まず、フラグをスタックに保存してリロードする必要があります。次に、これによりスタックポインタが動的に調整されるため、スタックにスピルされた一時変数などを参照するためにフレームポインタを使用する必要があります。
新しいx86プロセッサでは、lahfおよびsahf命令を使用して、オーバーフローフラグ以外のすべてのフラグをスタックではなくレジスタに保存できます。次に、setoとaddを使用して、レジスタにオーバーフローフラグを保存および復元できます。これらを組み合わせることで、上記と同じ方法でフラグを保存および復元しますが、スタックではなく2つのレジスタを使用します。それでも、ほとんどの場合、pushfおよびpopfよりもわずかに安価ですが、非常に高価です。
Haswell、Zen、およびそれ以降のプロセッサのフラグレス代替¶
HaswellおよびZenプロセッサで使用可能なBMI2 x86命令セット拡張機能から始めて、フラグを設定しないシフト命令があります:shrx。これとlea命令を使用して、上記のコードシーケンスに類似したコードシーケンスを実装できます。ただし、最新のx86プロセッサのほとんどでは、or命令よりもシフト命令をディスパッチできるポートが少ないため、これらは依然としてわずかに遅くなります。
高速、単一レジスタアドレッシングモード
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
shrxq %rax, %rsi, %rsi # Shift away bits if misspeculating.
movl (%rsi), %edi
これにより、レジスタはゼロまたは1に折りたたまれ、アドレッシングモードのオフセット以外は9以下になります。つまり、完全なアドレスは(1 << 31) + 9未満であることのみが保証されます。OSは、これを考慮に入れて、下位アドレス空間の追加ページを保護することをお勧めします。
最適化¶
このアプローチのコストの大部分は、このようにロードをチェックすることから生じるため、これを最適化するように努めることが重要です。ただし、チェックを*適用*するための命令シーケンスを効率化すること(たとえば、pushfqおよびpopfqシーケンスを回避することにより)以外に、唯一の重要な最適化は、脆弱性を導入せずにチェックするロードを減らすことです。私たちはそれを達成するためにいくつかのテクニックを適用します。
コンパイル時定数スタックオフセットからのロードをチェックしない¶
この最適化は、固定フレームポインタオフセットを使用するロードのチェックをスキップすることで、x86に実装します。
この最適化の結果、スピルされたレジスタの再ロードやグローバルフィールドへのアクセスなどのパターンはチェックされません。これは非常に重要なパフォーマンス上の利点です。
依存ロードのチェックを行わない¶
この軽減戦略が有効な中核的な理由は、ロードされたアドレスに対してデータフローチェックを確立することです。ただし、これは、アドレス自体がすでにチェック付きロードを使用してロードされている場合、依存ロードがチェック付きロードと同じ基本ブロック内にあり、追加の保護述語がない限り、チェックする必要がないことを意味します。次のようなコードを考えてみましょう。
...
.LBB0_4: # %danger
movq (%rcx), %rdi
movl (%rdi), %edx
これは以下のように変換されます。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rcx # Mask the pointer if misspeculating.
movq (%rcx), %rdi # Hardened load.
movl (%rdi), %edx # Unhardened load due to dependent addr.
これは、%rdi を介したロードをチェックしません。そのポインタはすでにチェックされたロードに依存しているためです。
負荷の大きい大きなブロックを単一のlfenceで保護する¶
独立した保護を必要とし、*かつ*ロードアドレスの強化を必要とする(非常に)多数のロードで始まるブロックの先頭に、単一の lfence 命令を使用する価値があるかもしれません。ただし、実際にはこれは効果的でない可能性があります。強化によるレイテンシの増加は、*正しく*投機的に実行された場合の lfence のレイテンシを超える必要があります。しかし、その場合、lfence のコストは、投機的実行の完全な損失(少なくとも)になります。lfence の使用によるパフォーマンスコストに関するこれまでの証拠は、このトレードオフが理にかなうホットコードパターンがほとんど、あるいはまったくないことを示しています。
セキュリティモデルを破壊する魅力的な最適化¶
セキュリティモデルを維持できないため、うまくいかなかったいくつかの最適化が検討されました。特に、他の多くの最適化がそれに帰着するため、1つは議論する価値があります。
基本ブロックの*最初の*ロードのみをチェックできるかどうか疑問に思いました。チェックが意図したとおりに機能する場合、ハードウェアで仮想アドレス変換も行われない無効なポインタが形成されます。処理の非常に初期段階で障害が発生するはずです。おそらく、それは誤って推測されたパスが秘密をリークするのに間に合うように物事を停止させるでしょう。これは、プロセッサが基本的にアウトオブオーダーであるため、投機的ドメインでも機能しません。結果として、攻撃者は最初のアドレス計算自体をストールさせ、無関係なロード(秘密データの攻撃されたロードを含む)を任意の数だけ通過させることができます。
手続き間チェック¶
最新のx86プロセッサは、呼び出された関数内、および関数から戻りアドレスまでを推測的に実行することがあります。結果として、誤って推測された述語の後に発生するロードをチェックする方法が必要ですが、ロードと誤って推測された述語は異なる関数にあります。本質的に、述語状態追跡の手続き間一般化が必要です。関数の間で述語状態を渡す際の主な課題は、この軽減策をより展開しやすくするためにABIまたは呼び出し規約の変更を要求したくないこと、さらに、この方法で軽減されたコードを、軽減されていないコードと簡単に混在させたいことです。そして、軽減の価値を完全に失うことなく。
スタックポインタの高いビットに述語状態を埋め込む¶
ポインタを強化して述語状態を関数に渡したり関数から返したりするのと同じ手法を使用できます。スタックポインタは関数間で簡単に渡され、上位ビットが設定されているかどうかをテストして、誤った推測によってマークされているかどうかを検出できます。呼び出しサイトの命令シーケンスは次のようになります(誤って推測された状態値が -1 であると仮定します)。
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
shlq $47, %rax
orq %rax, %rsp
callq other_function
movq %rsp, %rax
sarq 63, %rax # Sign extend the high bit to all bits.
これは、最初に述語状態を関数を呼び出す前に %rsp の上位ビットに入れ、その後、%rsp の上位ビットから読み戻します。(投機的であるかどうかにかかわらず)正しく実行している場合、これらはすべてノーオペレーションです。誤って推測している場合、スタックポインタは負になります。正規のアドレスのままになるようにしますが、それ以外の場合は下位ビットはそのままにして、スタックの調整を妨げることなく正常に進行できるようにします。呼び出された関数内では、この述語状態を抽出し、戻り時にリセットできます。
other_function:
# prolog
callq other_function
movq %rsp, %rax
sarq 63, %rax # Sign extend the high bit to all bits.
# ...
.LBB0_N:
cmovneq %r8, %rax # Conditionally update predicate state.
shlq $47, %rax
orq %rax, %rsp
retq
このアプローチは、すべてのコードがこの方法で軽減されている場合に効果的であり、軽減されていないコードへの非常に限られた範囲にも耐えることができます(状態は軽減されていない関数に出入りしてラウンドトリップしますが、更新されません)。しかし、いくつかの制限があります。状態を %rsp にマージするコストがかかり、軽減されたコードが軽減されていない呼び出し元の誤った推測から隔離されません。
この形式の手続き間軽減を使用することには、他にも利点があります。これらの無効なスタックポインタアドレスを形成することにより、投機的リターンがスタックに投機的に書き込まれた値を正常に読み取るのを防ぐことができます。これは、スタック上の戻りアドレスのアドレスの計算と述語状態の間にデータ依存関係を形成することによって最初に機能します。そして、満たされたとしても、誤予測によって状態が汚染された場合、結果のスタックポインタは無効になります。
内部関数のAPIを書き直して、述語状態を直接伝播する¶
(まだ実装されていません。)
内部関数では、述語を引数として受け入れて返すようにAPIを直接調整するオプションがあります。これは、関数に入るために %rsp に埋め込むよりもわずかに安価になる可能性があります。
lfence を使用して関数の遷移を保護する¶
lfence 命令は、後続のロードが、以前のすべての誤って予測された述語が解決されるまで、投機的に実行されないようにするために使用できます。このより広範なバリアを使用して、関数間で実行される投機的ロードを防止できます。呼び出しを処理するためにエントリブロックに、そして各リターンの前に発行します。このアプローチは、軽減された関数に入るすべての誤った推測を停止することにより、軽減されていないコードと混合した場合に最強の軽減を提供するという利点もあります。呼び出し元で何が起こったかに関係なく。ただし、そのような混合物は本質的により危険です。この種の混合物が十分な軽減策であるかどうかは、慎重な分析が必要です。
残念ながら、実験結果によると、このアプローチのパフォーマンスオーバーヘッドは、特定のパターンコードに対して非常に高いです。典型的な例は、あらゆる形式の再帰的評価エンジンです。ホットで高速な呼び出しとリターンシーケンスは、lfence で軽減されると、劇的なパフォーマンスの低下を示します。このコンポーネントだけでもパフォーマンスが2倍以上低下する可能性があり、コードの混合でのみ使用される場合でも不快なトレードオフになります。
内部TLSロケーションを使用して述語状態を渡す¶
関数間で述語状態を保持するために、特別なスレッドローカル値を定義できます。これは、呼び出し元と呼び出し先の間にサイドチャネルを使用して述語状態を通信することにより、ABIへの直接的な影響を回避します。また、状態の暗黙的なゼロ初期化も可能になり、チェックされていないコードを最初に実行できます。
ただし、これには、エントリブロックでのTLSからのロード、すべての呼び出しとすべてのリターン前のTLSへのストア、およびすべての呼び出し後のTLSからのロードが必要です。結果として、%rsp を使用する場合よりも、さらには関数エントリブロック内で lfence を使用する場合よりも、大幅にコストがかかると予想されます。
新しいABIまたは呼び出し規約を定義する¶
述語状態を明示的に関数に渡したり関数から返したりするために、新しいABIまたは呼び出し規約を定義できます。代替案のいずれも適切なパフォーマンスがない場合、これは興味深いものになる可能性がありますが、展開と採用が劇的に複雑になり、実行不可能になる可能性があります。
高レベルの代替軽減戦略¶
バリアント1攻撃を軽減するためのまったく異なる代替アプローチがあります。ほとんどの 議論 は、Linuxカーネル(または他のカーネル)の既知の攻撃可能な特定のコンポーネントを、脆弱でない命令シーケンスを含むようにコードを手動で書き直すことによって軽減することに焦点を当てています。 x86システムの場合、これは、投機的に実行された場合にデータをリークするコードパスに沿って lfence 命令を挿入するか、メモリアクセスを書き直して、既知の安全な領域への分岐のないマスキングを行うことによって行われます。 Intelシステムでは、lfence は 秘密データの投機的ロードを防ぎます。 AMDシステムでは、lfence は現在ノーオペレーションですが、MSRを設定することでディスパッチシリアライジングにすることができ、したがってコードパスの誤った推測を防ぐことができます(軽減策G-2 + V1-1)。
しかし、これは、情報漏洩攻撃を受ける可能性のあるコード内のすべてのポイントを見つけて列挙することに依存します。場合によっては、静的分析でこれを大規模に行うことが有効ですが、多くの場合、コードが脆弱であるかどうかを判断するには、依然として人間の判断に頼っています。特に、詳細な精査は受けていないものの、これらの攻撃に対して脆弱なままであるソフトウェアシステムの場合、これは非現実的なセキュリティモデルであると考えられます。自動的かつ体系的な緩和戦略が必要です。
条件分岐における自動lfence¶
既存の手動による緩和策を拡張する自然な方法は、すべての条件分岐のターゲットとフォールスルーの両方の宛先にlfence命令を挿入することです。これにより、述語または境界チェックが投機的にバイパスされることがなくなります。しかし、このアプローチのパフォーマンスオーバーヘッドは、簡単に言うと、壊滅的です。それでも、この取り組み以前には知られている唯一の真に「デフォルトで安全な」アプローチであり、パフォーマンスのベースラインとして機能します。
このパフォーマンスオーバーヘッドに対処し、より現実的に展開できるようにするための試みの1つは、MSVCの/Qspectreスイッチです。彼らの手法は、コンパイラ内で静的分析を使用して、攻撃を受けるリスクのある条件分岐にのみlfence命令を挿入することです。しかし、初期の 分析では、このアプローチは不完全であり、初期の概念実証と非常によく似た攻撃可能なパターンのごく一部しか捕捉できないことが示されています。そのため、パフォーマンスは許容範囲内ですが、適切な体系的な緩和策ではないようです。
パフォーマンスオーバーヘッド¶
このスタイルの包括的な緩和策のパフォーマンスオーバーヘッドは非常に高くなります。しかし、lfence命令などの従来推奨されていたアプローチと比較すると、非常に優れています。ユーザーがlfenceのスコープを制限してパフォーマンスへの影響を制御できるのと同様に、この緩和策のスコープも制限できます。
ただし、完全に緩和されたベースラインを得るためにどのようなコストがかかるかを理解することが重要です。ここでは、Haswell(またはそれ以降)のプロセッサをターゲットとし、パフォーマンスを向上させるためのすべてのトリックを使用すると仮定します(そのため、下位2GBは保護されず、プログラム内のPCの周囲+/- 2GBになります)。Googleのマイクロベンチマークスイートと、ThinLTOとPGOを使用して構築された高度にチューニングされた大規模サーバーの両方を実行しました。すべてはBMI2命令にアクセスできるように-march=haswellでビルドされ、ベンチマークは大規模なHaswellサーバーで実行されました。lfenceベースの緩和策と、ここで示すロード強化の両方でデータを収集しました。要約すると、ロード強化による緩和はlfenceによる緩和よりも1.77倍高速であり、通常のプログラムと比較したロード強化のオーバーヘッドは、ほとんどの大規模アプリケーションで30%以下のオーバーヘッドで、10%から50%の間になる可能性があります。
ベンチマーク |
|
ロード強化 |
緩和による高速化 |
|---|---|---|---|
Googleマイクロベンチマークスイート |
-74.8% |
-36.4% |
2.5倍 |
大規模サーバーQPS(ThinLTOとPGOを使用) |
-62% |
-29% |
1.8倍 |
以下は、マイクロベンチマークスイートの結果を視覚化したもので、要約では多少失われてしまう結果の分布を示しています。y軸は、lfenceに対するロード強化の速度比の対数スケールです(上 -> 高速 -> 良好)。各ボックスとひげは、多くの異なるメトリックが測定されている可能性のある1つのマイクロベンチマークを表しています。赤い線は中央値、ボックスは第1四分位数と第3四分位数、ひげは最小値と最大値を示します。
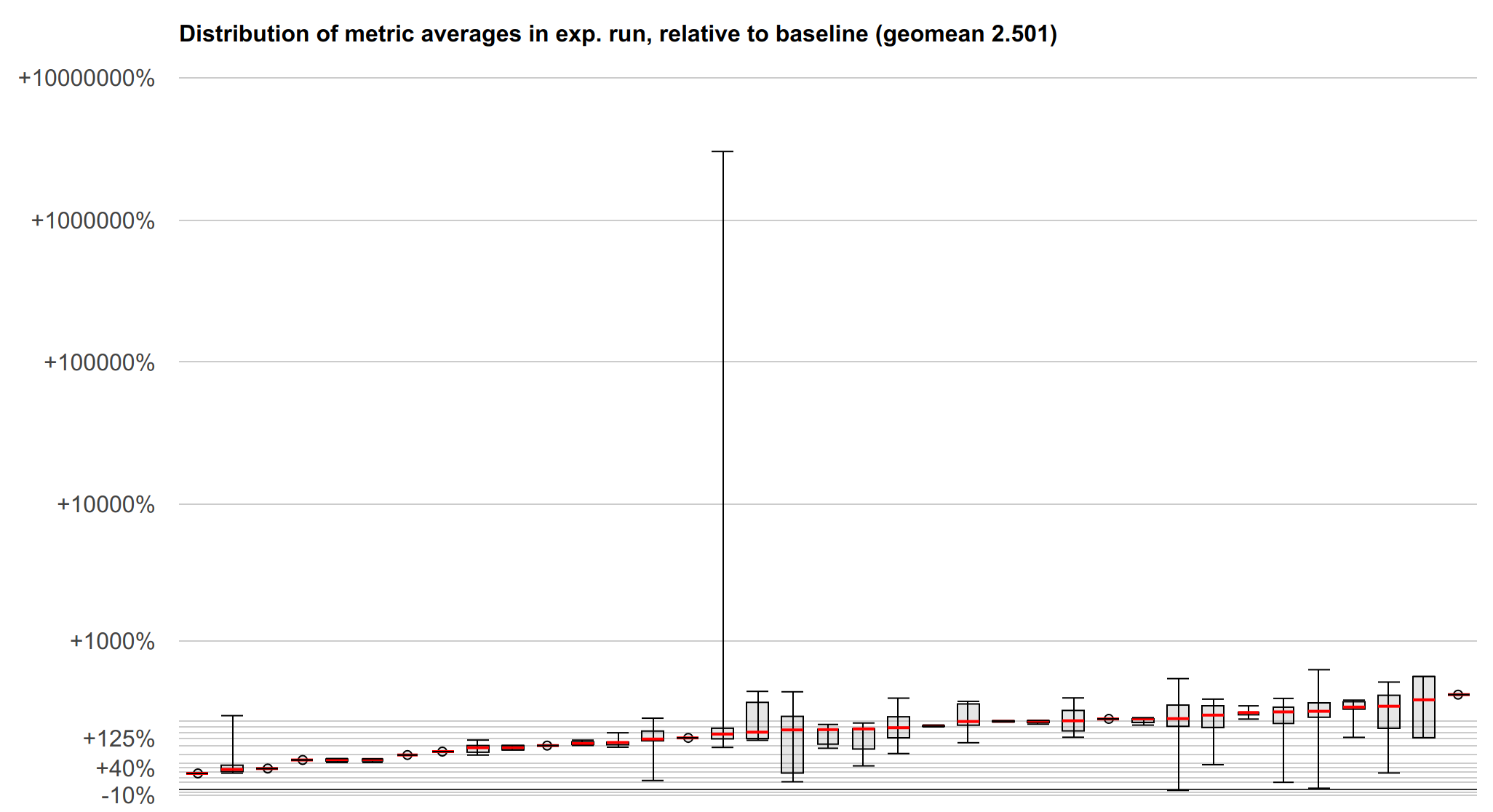
SPECまたはLLVMテストスイートのベンチマークデータはまだありませんが、取得に取り組むことができます。それでも、上記はパフォーマンスをかなり明確に示しているはずであり、特定のベンチマークで特に興味深い特性が明らかになる可能性は低いでしょう。
今後の課題:きめ細かい制御とAPI統合¶
この手法のパフォーマンスオーバーヘッドは非常に大きくなる可能性があり、ユーザーが制御または削減したいものです。ここには、使用される実装戦略に影響を与える興味深いオプションがあります。
特に魅力的なオプションの1つは、インライン化の決定をインテリジェントに処理するなど、関数単位などのかなり細かい粒度で、この緩和策のオプトインとオプトアウトの両方を許可することです。保護されたコードは保護されていないコードにインライン化されないようにすることができ、保護されていないコードは保護されたコードにインライン化されるときに保護されます。外部から制御される入力によって到達可能なコードのセットが限られているシステムでは、アプリケーションの全体的なセキュリティを損なうことなく、このようなメカニズムによって緩和の範囲を制限できる可能性があります。また、パフォーマンスへの影響は、アプリケーションの残りの部分が自動保護を受ける一方で、パフォーマンスオーバーヘッドの低い方法で手動で緩和できる少数の主要な関数に集中する可能性があります。
緩和の範囲を制限する場合でも、ホット関数を手動で緩和する場合でも、緩和を完全に無効にすることなく、緩和されたコードと緩和されていないコードを混在させるためのサポートが必要です。最初のユースケースでは、緩和されていないコードからの誤った推測中に呼び出されたときに、緩和されたコードが安全なままであることが特に望ましいでしょう。
2番目のユースケースでは、自動緩和手法をhttp://wg21.link/p0928(またはその他の最終的なAPI)で説明されているような明示的な緩和APIに接続して、すぐに穴を露出することなく、自動緩和から手動緩和に切り替えるためのクリーンな方法を提供することが重要になる場合があります。ただし、これを行う方法の設計は、APIがより確立されるまで考え出すのが困難です。これらのAPIが成熟するにつれて、これを見直します。