LLVMにおける自動ベクトル化¶
LLVMには、ループを対象とするループベクトル化器と、SLPベクトル化器の2つのベクトル化器があります。これらのベクトル化器は、異なる最適化の機会に焦点を当て、異なる手法を使用します。SLPベクトル化器は、コードに見つかった複数のスカラーをベクトルにマージするのに対し、ループベクトル化器はループ内の命令を拡張して、複数の連続する反復処理を実行します。
ループベクトル化器とSLPベクトル化器の両方がデフォルトで有効になっています。
ループベクトル化器¶
使用方法¶
ループベクトル化器はデフォルトで有効になっていますが、clangではコマンドラインフラグを使用して無効にすることができます。
$ clang ... -fno-vectorize file.c
コマンドラインフラグ¶
ループベクトル化器は、コストモデルを使用して最適なベクトル化ファクターとアンロールファクターを決定します。しかし、ベクトル化器のユーザーは、ベクトル化器に特定の値を使用するように強制することができます。「clang」と「opt」の両方で以下のフラグがサポートされています。
ユーザーは、コマンドラインフラグ「-force-vector-width」を使用して、ベクトル化SIMD幅を制御できます。
$ clang -mllvm -force-vector-width=8 ...
$ opt -loop-vectorize -force-vector-width=8 ...
ユーザーは、コマンドラインフラグ「-force-vector-interleave」を使用して、アンロールファクターを制御できます。
$ clang -mllvm -force-vector-interleave=2 ...
$ opt -loop-vectorize -force-vector-interleave=2 ...
プラグマループヒントディレクティブ¶
#pragma clang loop ディレクティブを使用すると、後続のforループ、whileループ、do-whileループ、またはC++11範囲ベースのforループに対して、ループベクトル化のヒントを指定できます。このディレクティブでは、ベクトル化とインターリーブを有効または無効にできます。ベクトル幅とインターリーブカウントも手動で指定できます。次の例では、ベクトル化とインターリーブを明示的に有効にしています。
#pragma clang loop vectorize(enable) interleave(enable)
while(...) {
...
}
次の例では、ベクトル幅とインターリーブカウントを指定することで、ベクトル化とインターリーブを暗黙的に有効にしています。
#pragma clang loop vectorize_width(2) interleave_count(2)
for(...) {
...
}
詳細は、Clangの言語拡張を参照してください。
診断¶
複雑な制御フロー、ベクトル化できない型、ベクトル化できない呼び出しなどを持つループの多くはベクトル化できません。ループベクトル化器は、コマンドラインオプションを使用してクエリできる最適化に関する情報を生成し、ループベクトル化器によってスキップされたループを識別し、診断します。
最適化に関する情報は、以下を使用して有効にします。
-Rpass=loop-vectorize は、正常にベクトル化されたループを識別します。
-Rpass-missed=loop-vectorize は、ベクトル化に失敗したループを識別し、ベクトル化が指定されていたかどうかを示します。
-Rpass-analysis=loop-vectorize は、ベクトル化の失敗原因となったステートメントを識別します。-fsave-optimization-record も指定されている場合、ベクトル化失敗の複数の原因がリストされる場合があります(この動作は将来変更される可能性があります)。
次のループを考えてみましょう。
#pragma clang loop vectorize(enable)
for (int i = 0; i < Length; i++) {
switch(A[i]) {
case 0: A[i] = i*2; break;
case 1: A[i] = i; break;
default: A[i] = 0;
}
}
コマンドライン-Rpass-missed=loop-vectorizeは、以下の情報を表示します。
no_switch.cpp:4:5: remark: loop not vectorized: vectorization is explicitly enabled [-Rpass-missed=loop-vectorize]
そして、コマンドライン-Rpass-analysis=loop-vectorizeは、switch文をベクトル化できないことを示します。
no_switch.cpp:4:5: remark: loop not vectorized: loop contains a switch statement [-Rpass-analysis=loop-vectorize]
switch(A[i]) {
^
行番号と列番号を生成するには、コマンドラインオプション-gline-tables-onlyと-gcolumn-infoを含めます。詳細は、Clangのユーザーマニュアルを参照してください。
機能¶
LLVMループベクトル化器には、複雑なループをベクトル化できる多くの機能があります。
ループ回数不明のループ¶
ループベクトル化器は、ループ回数不明のループをサポートしています。以下のループでは、反復startとfinishのポイントは不明であり、ループベクトル化器は0から始まらないループをベクトル化するためのメカニズムを持っています。この例では、「n」はベクトル幅の倍数ではない可能性があり、ベクトル化器は最後のいくつかの反復をスカラーコードとして実行する必要があります。ループのスカラーコピーを保持すると、コードサイズが増加します。
void bar(float *A, float* B, float K, int start, int end) {
for (int i = start; i < end; ++i)
A[i] *= B[i] + K;
}
ポインタの実行時チェック¶
以下の例では、ポインタAとBが連続したアドレスを指している場合、一部のAの要素が配列Bから読み取られる前に書き込まれるため、コードをベクトル化することはできません。
一部のプログラマーは、「restrict」キーワードを使用して、ポインタが分離されていることをコンパイラに通知しますが、この例では、ループベクトル化器はポインタAとBが一意であることを知る方法がありません。ループベクトル化器は、実行時に配列AとBが分離されたメモリ位置を指しているかどうかをチェックするコードを配置することで、このループを処理します。配列AとBがオーバーラップしている場合、ループのスカラーバージョンが実行されます。
void bar(float *A, float* B, float K, int n) {
for (int i = 0; i < n; ++i)
A[i] *= B[i] + K;
}
リダクション¶
この例では、sum変数はループの連続した反復によって使用されます。通常、これはベクトル化を妨げますが、ベクトル化器は「sum」がリダクション変数であることを検出できます。「sum」変数は整数ベクトルになり、ループの最後に配列の要素が加算されて正しい結果が生成されます。加算、乗算、XOR、AND、ORなど、さまざまなリダクション演算をサポートしています。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i] + 5;
return sum;
}
-ffast-mathが使用されている場合、浮動小数点リダクション演算をサポートしています。
インダクション¶
この例では、インダクション変数iの値が配列に保存されています。ループベクトル化器は、インダクション変数をベクトル化する方法を知っています。
void bar(float *A, int n) {
for (int i = 0; i < n; ++i)
A[i] = i;
}
IF変換¶
ループベクトル化器は、コード内のIF文を「平坦化」し、単一の命令ストリームを生成できます。ループベクトル化器は、最内ループ内の任意の制御フローをサポートします。最内ループには、IF、ELSE、GOTOなどの複雑なネストが含まれる場合があります。
int foo(int *A, int *B, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
if (A[i] > B[i])
sum += A[i] + 5;
return sum;
}
ポインタインダクション変数¶
この例では、標準C++ライブラリの「accumulate」関数を使用しています。このループは、整数インデックスではなく、ポインタであるC++イテレータを使用しています。ループベクトル化器はポインタインダクション変数を検出し、このループをベクトル化できます。この機能は、多くのC++プログラムがイテレータを使用するため重要です。
int baz(int *A, int n) {
return std::accumulate(A, A + n, 0);
}
逆イテレータ¶
ループベクトル化器は、逆方向にカウントするループをベクトル化できます。
void foo(int *A, int n) {
for (int i = n; i > 0; --i)
A[i] +=1;
}
スキャター/ギャザー¶
ループベクトル化器は、メモリをスキャター/ギャザーするスカラー命令のシーケンスになるコードをベクトル化できます。
void foo(int * A, int * B, int n) {
for (intptr_t i = 0; i < n; ++i)
A[i] += B[i * 4];
}
多くの場合、コストモデルはLLVMにこれが有益ではないことを通知し、LLVMは「-mllvm -force-vector-width=#」で強制されない限り、そのようなコードをベクトル化しません。
混合型のベクトル化¶
ループベクトル化器は、混合型のプログラムをベクトル化できます。ベクトル化器のコストモデルは、型変換のコストを推定し、ベクトル化が有利かどうかを判断できます。
void foo(int *A, char *B, int n) {
for (int i = 0; i < n; ++i)
A[i] += 4 * B[i];
}
グローバル構造体のエイリアス解析¶
グローバル構造体へのアクセスもベクトル化できます。エイリアス解析を使用して、アクセスがエイリアスを作成しないことを確認します。ポインタアクセスから構造体メンバーへの実行時チェックを追加することもできます。
多くのバリエーションがサポートされていますが、未定義の動作が無視される(他のコンパイラが行うように)ものに依存するものは、まだベクトル化されていません。
struct { int A[100], K, B[100]; } Foo;
void foo() {
for (int i = 0; i < 100; ++i)
Foo.A[i] = Foo.B[i] + 100;
}
関数呼び出しのベクトル化¶
ループベクトル化器は、固有の数学関数をベクトル化できます。これらの関数のリストについては、以下の表を参照してください。
pow |
exp |
exp2 |
sin |
cos |
sqrt |
log |
log2 |
log10 |
fabs |
floor |
ceil |
fma |
trunc |
nearbyint |
fmuladd |
これらの固有関数に対応する数学ライブラリ関数を、ライブラリ呼び出しが「errno」などの外部状態にアクセスする場合、最適化によってベクトル化できない場合があります。C/C++数学ライブラリ関数の最適化を向上させるには、「-fno-math-errno」を使用します。
ループベクトル化器はターゲット上の特別な命令を認識しており、命令にマップされる関数呼び出しを含むループをベクトル化します。たとえば、以下のループは、SSE4.1 roundps命令が使用可能な場合、Intel x86でベクトル化されます。
void foo(float *f) {
for (int i = 0; i != 1024; ++i)
f[i] = floorf(f[i]);
}
ベクトル化時の部分アンロール¶
最新のプロセッサは複数の実行ユニットを備えており、高度な並列性を持つプログラムのみがマシンの全幅を完全に活用できます。ループベクタライザは、ループの部分アンローリングを実行することにより、命令レベルの並列性(ILP)を向上させます。
以下の例では、配列全体が変数 'sum' に累積されます。これは、プロセッサが単一の実行ポートしか使用できないため非効率です。コードをアンローリングすることにより、ループベクタライザは2つ以上の実行ポートを同時に使用できるようにします。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i];
return sum;
}
ループベクタライザは、コストモデルを使用して、ループのアンローリングが有利かどうかを判断します。ループをアンローリングするかどうかは、レジスタの圧力と生成されるコードのサイズによって異なります。
エピローグベクタ化¶
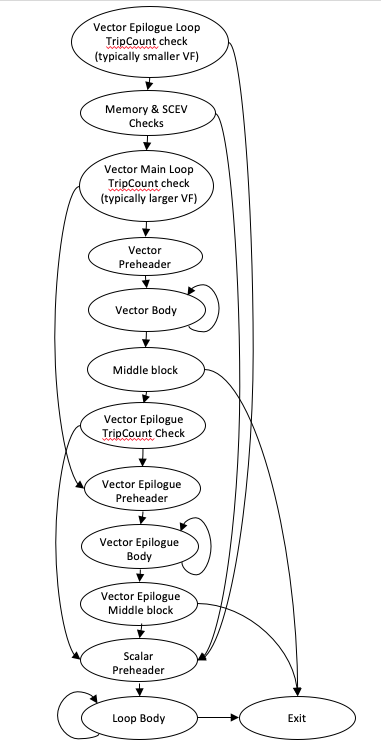
ループをベクタ化する際、ループの反復回数が不明な場合、またはループの反復回数がベクタ化とアンロール係数で均等に割り切れない場合、スカラー剰余(エピローグ)ループを実行する必要があります。ベクタ化とアンロール係数が大きい場合、反復回数の少ないループは、ベクタコードではなくスカラーコードで大部分の時間を費やす可能性があります。この問題に対処するために、内部ループベクタライザは、小さな反復回数を持つループでもベクタ化コードで実行される可能性を高めるベクタ化とアンロール係数の組み合わせでエピローグループをベクタ化できる機能で強化されています。下の図は、実行時チェックを含む典型的なエピローグベクタ化ループのCFGを示しています。図のように、制御フローは実行時のポインタチェックの重複を回避し、反復回数が非常に少ないループのパス長を最適化するように構成されています。
パフォーマンス¶
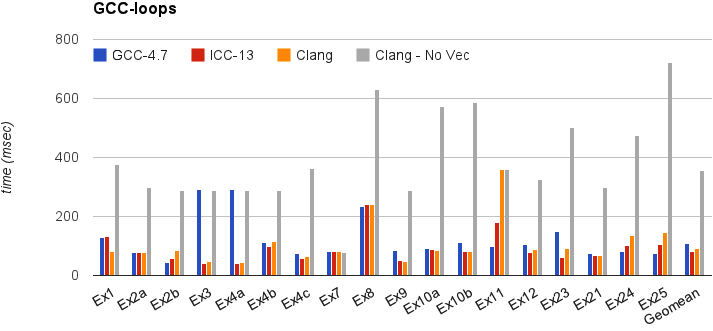
このセクションでは、単純なベンチマークでのClangの実行時間を示します:gcc-loops。このベンチマークは、Dorit NuzmanによるGCC自動ベクタ化ページからのループのコレクションです。
下のグラフは、ループベクタ化ありとなしで-O3に最適化され、「corei7-avx」用にチューニングされたSandybridge iMacで実行されるGCC-4.7、ICC-13、およびClang-SVNを比較しています。Y軸は時間をmsecで示しています。低い方が優れています。最後の列は、すべてのカーネルの幾何平均を示しています。
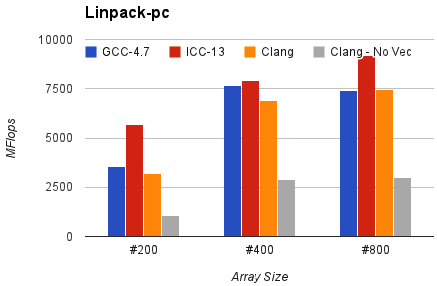
そして、同じ構成のLinpack-pc。結果はMflopsで、高い方が優れています。
今後の開発方向¶
- ベクタ化計画
LLVMのループベクタライザのプロセスをモデル化し、インフラストラクチャをアップグレードします。
SLPベクタライザ¶
詳細¶
SLPベクタ化(別名スーパーワードレベル並列処理)の目標は、類似した独立した命令をベクトル命令に結合することです。メモリアクセス、算術演算、比較演算、PHIノードはすべて、この手法を使用してベクタ化できます。
たとえば、次の関数は、入力(a1、b1)と(a2、b2)に対して非常に類似した操作を実行します。基本ブロックベクタライザは、これらをベクトル演算に結合する可能性があります。
void foo(int a1, int a2, int b1, int b2, int *A) {
A[0] = a1*(a1 + b1);
A[1] = a2*(a2 + b2);
A[2] = a1*(a1 + b1);
A[3] = a2*(a2 + b2);
}
SLPベクタライザは、結合するスカラーを検索するために、基本ブロック全体でボトムアップにコードを処理します。
使用方法¶
SLPベクタライザはデフォルトで有効になっていますが、clangではコマンドラインフラグを使用して無効にできます。
$ clang -fno-slp-vectorize file.c