LLVM ループ用語集(および標準形)¶
ループの定義¶
ループはコードオプティマイザにとって重要な概念です。LLVM では、制御フローグラフ内のループの検出は LoopInfo によって行われます。これは以下の定義に基づいています。
ループは、制御フローグラフ(CFG、ノードは基本ブロックを表す)からのノードのサブセットであり、以下の特性を持ちます。
誘導部分グラフ(ループ内の CFG からのすべてのエッジを含む部分グラフ)は強連結です(すべてのノードは他のすべてのノードから到達可能です)。
サブセットの外側からサブセットへのすべてのエッジは、**ヘッダー**と呼ばれる同じノードを指します。結果として、ヘッダーはループ内のすべてのノードを支配します(つまり、ループのノードへのすべての実行パスはヘッダーを通過する必要があります)。
ループは、これらの特性を持つ最大のサブセットです。つまり、CFG から追加のノードを追加しても、誘導部分グラフが強連結のままで、ヘッダーが同じままであることはできません。
コンピュータサイエンスの文献では、これはしばしば*自然ループ*と呼ばれます。LLVM では、より一般化された定義は サイクル と呼ばれます。
用語¶
ループの定義には、いくつかの追加の用語が付属しています。
**進入ブロック**(または**ループ先行ブロック**)は、ループ(必ずヘッダー)へのエッジを持つ非ループノードです。進入ブロックが1つだけで、その唯一のエッジがヘッダーへのものである場合、それはループの**プレヘッダー**とも呼ばれます。プレヘッダーは、ループの一部ではない状態でループを支配します。
**ラッチ**は、ヘッダーへのエッジを持つループノードです。
**バックエッジ**は、ラッチからヘッダーへのエッジです。
**退出エッジ**は、ループ内からループ外のノードへのエッジです。そのようなエッジのソースは**退出ブロック**と呼ばれ、そのターゲットは**出口ブロック**と呼ばれます。

重要な注意事項¶
このループ定義には、いくつかの注目すべき結果があります。
ノードは最大で1つのループのヘッダーになることができます。そのため、ループはそのヘッダーによって識別できます。ヘッダーはループへの唯一のエントリであるため、単一エントリ複数出口(SEME)領域と呼ぶことができます。
関数のエントリから到達できない基本ブロックの場合、ループの概念は未定義です。これは、支配の概念も未定義であることからきています。
最小のループは、自身に分岐する単一の基本ブロックで構成されます。この場合、そのブロックはヘッダー、ラッチ(そして別のブロックへの別のエッジがある場合は退出ブロック)を兼ねています。自身への分岐を持たない単一のブロックは、それが自明に強連結であっても、ループとは見なされません。

この場合、ヘッダー、退出ブロック、ラッチの役割は同じノードになります。 LoopInfo はこれを以下のように報告します。
$ opt input.ll -passes='print<loops>'
Loop at depth 1 containing: %for.body<header><latch><exiting>
ループは互いにネストすることができます。つまり、ループのノードセットは、異なるループヘッダーを持つ別のループのサブセットになることができます。関数内のループ階層はフォレストを形成します。各トップレベルループは、その中にネストされたループのツリーのルートです。

2つのループがノードのほんの一部だけを共有することはできません。2つのループは、互いに素であるか、一方が他方の内部にネストされています。以下の例では、左右のサブセットはどちらも最大条件に違反しています。両方のセットの結合のみがループと見なされます。

2つの論理ループがヘッダーを共有する可能性もありますが、LLVM では単一のループと見なされます。
for (int i = 0; i < 128; ++i)
for (int j = 0; j < 128; ++j)
body(i,j);
これは LLVM-IR では次のように表される場合があります。ヘッダーは1つしかないため、ループも1つだけであることに注意してください。

LoopSimplify パスはループを検出し、外側と内側のループに個別のヘッダーを確保します。

CFG 内のサイクルは、ループが存在することを意味するわけではありません。以下の例は、サイクル内の他のすべてのノードを支配するヘッダーノードが存在しない CFG を示しています。これは**還元不可能な制御フロー**と呼ばれます。

還元可能という用語は、3つの基本構造のいずれかを単一のノードで連続して置き換えることによって、CFG を単一のノードに縮小できることからきています。基本ブロックの順次実行、非巡回条件分岐(またはスイッチ)、および自身をループする基本ブロックです。Wikipedia には、より正式な定義があり、基本的にはすべてのサイクルには支配的なヘッダーがあるとされています。
還元不可能な制御フローは、ループのネストのどのレベルでも発生する可能性があります。つまり、ループ自体にループが含まれていなくても、その本体に巡回制御フローが存在する可能性があります。別のループ内にネストされていないループは、依然として外部サイクルの一部である可能性があります。また、一方が他方に含まれている2つのループの間に追加のサイクルが存在する可能性があります。ただし、LLVM サイクル は、ループと還元不可能な制御フローの両方をカバーします。
FixIrreducible パスは、新しいループヘッダーを挿入することによって、還元不可能な制御フローをループに変換できます。これはデフォルトの最適化パスパイプラインには含まれていませんが、一部のバックエンドターゲットでは必須です。
退出エッジは、ループから抜け出す唯一の方法ではありません。他の可能性としては、到達不能なターミネータ、[[noreturn]] 関数、例外、シグナル、そしてコンピュータの電源ボタンなどがあります。
ループに戻るパス(つまり、ラッチまたはヘッダーへのパス)を持たないループ「内」の基本ブロックは、ループの一部とは見なされません。これは次のコードで示されています。
for (unsigned i = 0; i <= n; ++i) {
if (c1) {
// When reaching this block, we will have exited the loop.
do_something();
break;
}
if (c2) {
// abort(), never returns, so we have exited the loop.
abort();
}
if (c3) {
// The unreachable allows the compiler to assume that this will not rejoin the loop.
do_something();
__builtin_unreachable();
}
if (c4) {
// This statically infinite loop is not nested because control-flow will not continue with the for-loop.
while(true) {
do_something();
}
}
}
制御フローが最終的にループを離れるという要件はありません。つまり、ループは無限になる可能性があります。**静的に無限ループ**とは、退出エッジを持たないループです。**動的に無限ループ**は退出エッジを持ちますが、それが取られない可能性があります。これは、以下のコードの n == UINT_MAX など、特定の状況下でのみ発生する可能性があります。
for (unsigned i = 0; i <= n; ++i)
body(i);
オプティマイザは、たとえば退出条件が常に偽であることを証明できる場合、動的に無限ループを静的に無限ループに変換できます。退出エッジが取られないため、オプティマイザは条件分岐を無条件分岐に変更できます。
ループに llvm.loop.mustprogress メタデータで注釈が付けられている場合、コンパイラは証明できなくても、最終的に終了すると想定できます。たとえば、プログラムが永遠にそのループでスタックする可能性があっても、本体に副作用のない mustprogress ループを削除できます。C や C++ などの言語は、一部のループに対してこのような前進保証を持っています。また、mustprogress および willreturn 関数属性、および古い llvm.sideeffect 組み込み関数も参照してください。
ループを離れる前にループヘッダーが実行される回数は、**ループトリップカウント**(または**反復回数**)です。ループをまったく実行しない場合は、**ループガード**がループ全体をスキップする必要があります。

ループヘッダーが行う最初のことは、別の実行があるかどうかを確認し、ない場合はすぐに作業を行わずに終了することであるため(回転ループ も参照)、ループトリップカウントはループの反復回数の最適な尺度ではありません。たとえば、以下のコードの非正の n に対するヘッダー実行回数(ループ回転前)は、ループ本体がまったく実行されない場合でも 1 です。
for (int i = 0; i < n; ++i)
body(i);
より良い尺度は**バックエッジ取得カウント**であり、これはループの前にバックエッジのいずれかが取られた回数です。これは、ヘッダーに入る実行のトリップカウントより 1 少ないです。
LoopInfo¶
LoopInfo は、ループに関する情報を取得するためのコア分析です。上記の定義には、このインターフェースをうまく操作するために重要な意味を持つものがいくつかあります。
LoopInfo は、非ループサイクルに関する情報は含んでいません。結果として、正確性のために完全なサイクル検出を必要とするアルゴリズムには適していません。
LoopInfo は、すべてのトップレベルループ(たとえば、他のループに含まれていないループ)を列挙するためのインターフェースを提供します。そこから、そのトップレベルループにルート化されたサブループのツリーを歩くことができます。
最適化中に静的に到達不能になるループは、LoopInfo から*削除する必要があります*。何らかの理由でこれができない場合、最適化はループの静的到達可能性を*維持する必要があります*。
ループ簡略化形式¶
ループ簡略化形式は、いくつかの解析と変換をよりシンプルかつ効果的にする標準形式です。これはLoopSimplify(-loop-simplify)パスによって保証され、LoopPassをスケジューリングする際にパスマネージャによって自動的に追加されます。このパスはLoopSimplify.hに実装されています。成功した場合、ループは次のようになります。
プレヘッダーを持つ。
単一のバックエッジを持つ(これは単一のラッチが存在することを意味する)。
専用の出口を持つ。つまり、ループの出口ブロックには、ループの外側にある先行ブロックがありません。これは、すべての出口ブロックがループヘッダーによって支配されていることを意味します。
ループ閉じたSSA(LCSSA)¶
プログラムは、SSA形式であり、ループ内で定義されたすべての値がこのループ内でのみ使用される場合、ループ閉じたSSA形式になります。
LLVM IRで記述されたプログラムは常にSSA形式ですが、必ずしもLCSSA形式ではありません。後者を実現するために、ループ境界を越えて有効な各値について、単一エントリPHIノードが各出口ブロックに挿入され[1]、これらの値をループ内で「閉じ」ます。特に、次のループを考えてみましょう。
c = ...;
for (...) {
if (c)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2); // X3 defined
}
... = X3 + 4; // X3 used, i.e. live
// outside the loop
内側のループでは、X3はループ内で定義されていますが、ループの外側で使用されています。ループ閉じたSSA形式では、これは次のように表されます。
c = ...;
for (...) {
if (c)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2);
}
X4 = phi(X3);
... = X4 + 4;
これは依然として有効なLLVMです。追加のPHIノードは完全に冗長ですが、すべてのLoopPassはそれらを保持する必要があります。この形式はLCSSA(-lcssa)パスによって保証され、LoopPassをスケジューリングする際にLoopPassManagerによって自動的に追加されます。ループの最適化が完了した後、これらの追加のPHIノードは-instcombineによって削除されます。
出口ブロックはループの外側にあるため、そのようなPHIはループの外側で値を使用するため、どのようにループ内で値を「閉じ」ることができるのでしょうか?まず、PHIノードについては、LangRefで述べられているように、「各入力値の使用は、対応する先行ブロックから現在のブロックへのエッジで発生すると見なされます」。ここで、出口ブロックへのエッジはループの外側にあると見なされます。なぜなら、そのエッジを取ると、明らかにループから外れるからです。
ただし、エッジには実際にはIRが含まれていないため、ソースコードでは、使用が現在のブロックで発生するか、それぞれの先行ブロックで発生するかの規則を選択する必要があります。LCSSAの目的のために、私たちは後者で使用が発生すると考えます(使用を内部と見なすため)[2]。
LCSSAの主な利点は、他の多くのループ最適化を簡素化することです。
まず、すべての外部ユーザーを確認する必要がある場合、出口ブロック内のすべての(ループクローズ)PHIノードを反復処理するだけでよいという単純な観察があります(代替手段は、ループ内のすべての命令の定義使用チェーン[3]をスキャンすることです)。
次に、たとえば、上記のループをsimple-loop-unswitchすることを考えてみましょう。LCSSA形式であるため、ループ内で定義された値は、ループ内またはループクローズPHIノードでのみ使用されることがわかります。この場合、ループクローズPHIノードはX4のみです。これは、ループをコピーしてX4を次のように変更するだけでよいことを意味します。
c = ...;
if (c) {
for (...) {
if (true)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2);
}
} else {
for (...) {
if (false)
X1' = ...
else
X2' = ...
X3' = phi(X1', X2');
}
}
X4 = phi(X3, X3')
これで、X4のすべての使用は更新された値を取得します(一般に、ループがLCSSA形式の場合、ループ変換では、変更を有効にするためにループクローズPHIノードを更新するだけで済みます)。ループ閉じたSSA形式がない場合、X3がループの外側で使用される可能性があることを意味します。そのため、X4(新しいX3)を導入し、X3のすべての使用をそれで置き換える必要があります。ただし、LLVMは各値の定義使用チェーン[3]を保持しているため、データフロー分析を実行してすべての使用を見つけて置き換える必要はありません(この変換を実行するユーティリティ関数replaceAllUsesWith()さえあります。定義使用チェーンを反復処理することにより)。
もう1つの重要な利点は、誘導変数のすべての使用の動作が同じであることです。これがなければ、変数が定義されているループの外側で使用される場合を区別する必要があります。たとえば、
for (i = 0; i < 100; i++) {
for (j = 0; j < 100; j++) {
k = i + j;
use(k); // use 1
}
use(k); // use 2
}
通常のSSA形式で外側のループから見ると、kの最初の使用は適切に動作していませんが、2番目の使用はベース100、ステップ1の誘導変数です。ただし、実際には、LLVMコンテキストでは、このようなケースはSCEVによって効果的に処理できます。Scalar Evolution(scalar-evolution)またはSCEVは、ループにおけるスカラー式の進化を分析および分類する(分析)パスです。
一般に、LCSSA形式のループではSCEVを使用する方が簡単です。SCEVが分析できるスカラー(ループバリアント)式の進化は、定義上、ループに対して相対的です。式はLLVMでllvm::Instructionによって表されます。式が2つ(以上)のループ内にある場合(ループが上記の例のようにネストされている場合にのみ発生する可能性があります)、進化の分析(SCEVから)を取得するには、どのループに対して相対的かを指定する必要があります。具体的には、getSCEVAtScope()を使用する必要があります。
ただし、すべてのループがLCSSA形式の場合、各式は実際には2つの異なるllvm::Instructionsによって表されます。1つはループ内、もう1つはループ外のループクローズPHIノードで、最後の反復後の式の値を表します(事実上、各ループバリアント式を2つの式に分割するため、すべての式は最大で1つのループにあります)。これで、getSCEV()を使用できます。これらの2つのllvm::Instructionsのどちらに渡すかによって、コンテキスト/スコープ/相対ループが明確になります。
脚注
「より標準的な」ループ¶
回転ループ¶
ループはLoopRotate(loop-rotate)パスによって回転されます。これはループをdo / whileスタイルのループに変換し、LoopRotation.hに実装されています。例:
void test(int n) {
for (int i = 0; i < n; i += 1)
// Loop body
}
は次のように変換されます。
void test(int n) {
int i = 0;
do {
// Loop body
i += 1;
} while (i < n);
}
警告:この変換は、コンパイラがループ本体が少なくとも1回実行されることを証明できる場合にのみ有効です。そうでない場合、実行時にテストするガードを挿入する必要があります。上記の例では、それは次のようになります。
void test(int n) {
int i = 0;
if (n > 0) {
do {
// Loop body
i += 1;
} while (i < n);
}
}
LLVM IRレベルでのループ回転の影響を理解することが重要です。制御フローグラフ(CFG)のグラフィカル表現も提供しながら、LLVM IRの前の例に従います。 view-cfgパスを利用することで、同じグラフィカルな結果を得ることができます。
初期の for ループは次のように変換できます。
define void @test(i32 %n) {
entry:
br label %for.header
for.header:
%i = phi i32 [ 0, %entry ], [ %i.next, %latch ]
%cond = icmp slt i32 %i, %n
br i1 %cond, label %body, label %exit
body:
; Loop body
br label %latch
latch:
%i.next = add nsw i32 %i, 1
br label %for.header
exit:
ret void
}
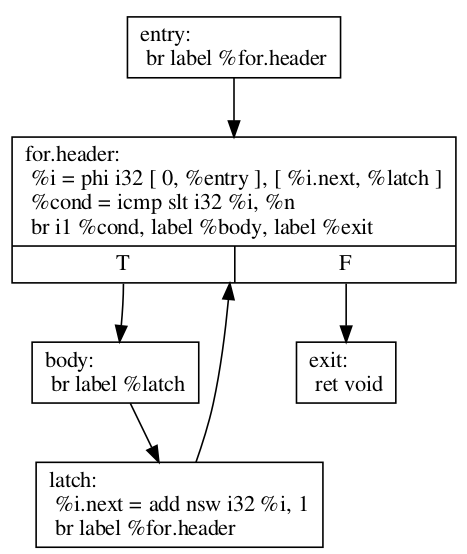
LoopRotateが実際にこのループをどのように変換するかを説明する前に、do-whileスタイルのループに(手動で)変換する方法を説明します。
define void @test(i32 %n) {
entry:
br label %body
body:
%i = phi i32 [ 0, %entry ], [ %i.next, %latch ]
; Loop body
br label %latch
latch:
%i.next = add nsw i32 %i, 1
%cond = icmp slt i32 %i.next, %n
br i1 %cond, label %body, label %exit
exit:
ret void
}
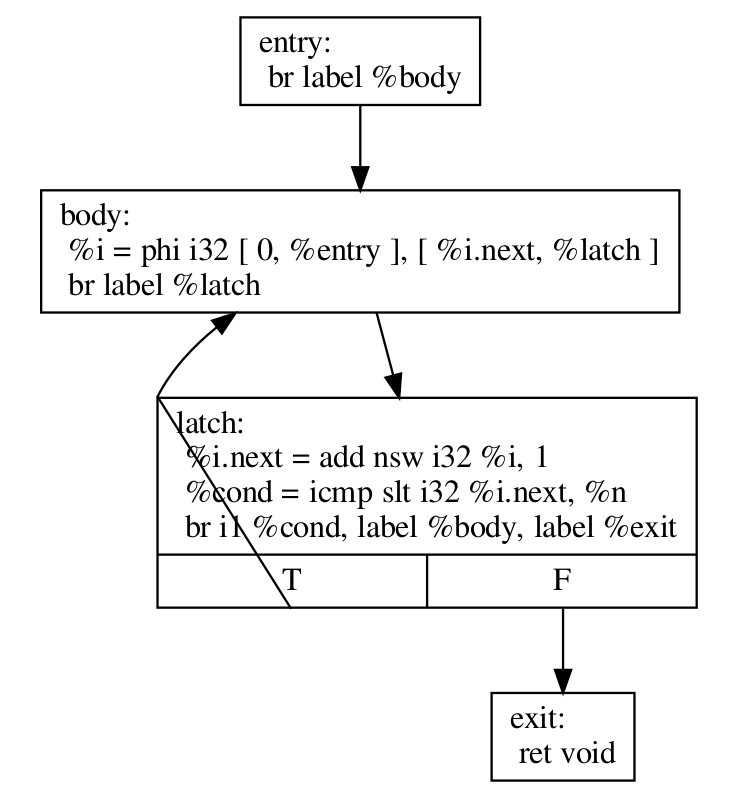
2つのことに注意してください
条件チェックはループの「下部」、つまりラッチに移動されました。これは、LoopRotateがループのヘッダーをラッチにコピーすることによって行うことです。
この場合、コンパイラはループが少なくとも1回は確実に実行されると推測できないため、上記の変換は無効です。上記のように、ガードを挿入する必要があります。これはLoopRotateが行うことです。
LoopRotateはこのループを次のように変換します。
define void @test(i32 %n) {
entry:
%guard_cond = icmp slt i32 0, %n
br i1 %guard_cond, label %loop.preheader, label %exit
loop.preheader:
br label %body
body:
%i2 = phi i32 [ 0, %loop.preheader ], [ %i.next, %latch ]
br label %latch
latch:
%i.next = add nsw i32 %i2, 1
%cond = icmp slt i32 %i.next, %n
br i1 %cond, label %body, label %loop.exit
loop.exit:
br label %exit
exit:
ret void
}
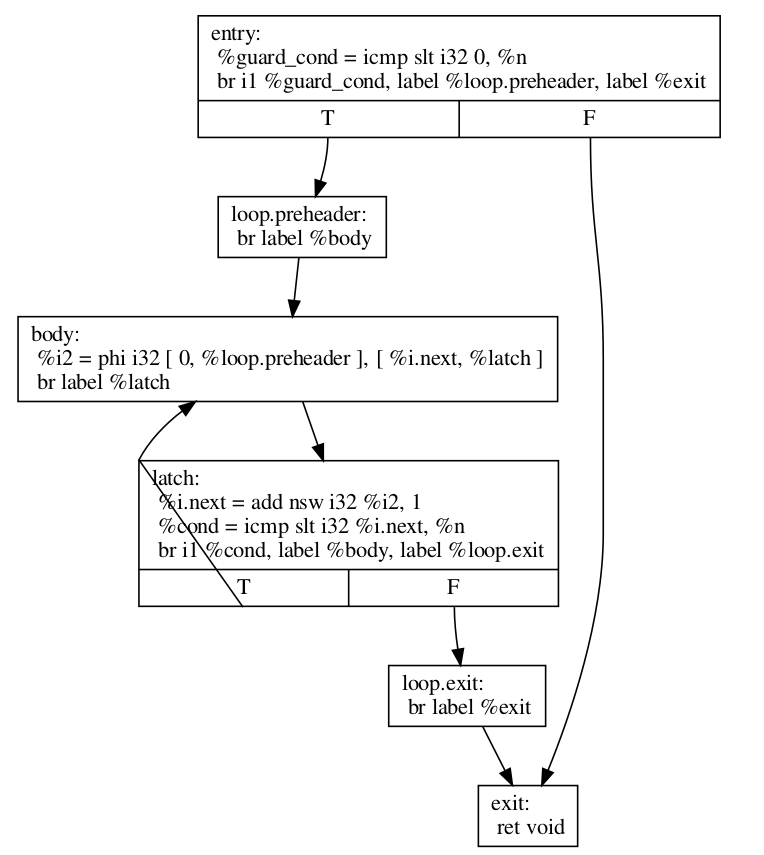
結果は、LoopRotateが回転後にループがループ簡略化形式になることを保証するため、予想よりも少し複雑になります。この場合、ループにプレヘッダーを持たせるために%loop.preheader基本ブロックを挿入し、ループに専用の出口を持たせるために%loop.exit基本ブロックを導入しました(そうでない場合、%exitは%latchと%entryの両方からジャンプされますが、%entryはループに含まれていません)。LoopRotateを正常に適用するには、ループが事前にループ簡略化形式である必要があります。
この形式の主な利点は、不変命令、特にロードをプレヘッダーにホイストできることです。これは回転していないループでも実行できますが、いくつかの欠点があります。例を使って説明しましょう。
for (int i = 0; i < n; ++i) {
auto v = *p;
use(v);
}
pからのロードは不変であり、use(v)はvを使用するステートメントであると仮定します。ロードを1回だけ実行したい場合は、ループ本体の「外側」に移動して、次のようになります。
auto v = *p;
for (int i = 0; i < n; ++i) {
use(v);
}
しかし、現在の形式では、n <= 0 の場合、ループ本体は決して実行されず、そのためロードも実行されません。これは主に意味的な理由で問題となります。n <= 0 で、p からのロードが無効な場合を考えてみましょう。初期プログラムではエラーは発生しません。しかし、この変換を行うとエラーが発生し、初期のセマンティクスが事実上壊れてしまいます。
これらの問題を両方とも回避するために、ガードを挿入することができます。
if (n > 0) { // loop guard
auto v = *p;
for (int i = 0; i < n; ++i) {
use(v);
}
}
これは確かに改善されていますが、もう少し改善することができます。n が 0 より大きいかどうかのチェックが2回実行されていることに注目してください(そして n はその間変化しません)。ガード条件をチェックするときと、ループの最初の実行時の2回です。これを回避するために、最初の反復を無条件で実行し、ループ条件を最後に挿入することができます。これは事実上、ループを do-while ループに変換することを意味します。
if (0 < n) {
auto v = *p;
do {
use(v);
++i;
} while (i < n);
}
LoopRotate は一般的にこのような巻き上げを行わないことに注意してください。むしろ、これはループ不変コード移動(-licm)のような他のパスを有効にするための変換です。